
HyperFlow AIの技術 ①
生成AIアプリケーション開発における中核的な課題は、オーケストレーションと運用構造にあります。HyperFlowは、この複雑性をフローグラフとして可視化するノーコード開発プラットフォームであり、生成AIシステムを構造的に設計できるようにします。
生成AIは、もはや選択肢ではなく必須の技術となりました。チャットボット、検索、カスタマーサポート、文書処理、コンテンツ生成、ナレッジDB構築に至るまで、生成AIはすでに実際のビジネスの中核で機能しています。しかし皮肉なことに、AIモデルがますます高度化する一方で、AIアプリケーションの開発はむしろ難しくなっています。本稿では、その課題の原因を整理し、HyperFlow AIがこの複雑さを「技術アーキテクチャ」のレベルでどのように再設計しているのか、そしてその基盤となる中核的な技術コンセプトについて解説します。
生成AIアプリ開発の現実:「モデル」ではなく「接続」が問題
生成AIアプリケーションを本格的に構築するためには、何が必要でしょうか。
- LLM(OpenAI、Claude、Gemini など)
- 埋め込み(Embedding)モデル
- ベクトルデータベース
- ドキュメントのパースおよびセグメント分割
- RAGによる検索および再ランキング
- プロンプトテンプレート管理
- パラメータチューニング
- ログ、コスト、パフォーマンスの追跡
- 安定したデプロイおよび運用環境
これらの要素が有機的に接続されてはじめて、1つの生成AIアプリケーションが完成します。問題は、これらすべてが異なるサービス、異なるインターフェース、異なる制約条件の上で動作している点にあります。その結果、開発者は数千行に及ぶボイラープレートコードを書く必要があり、1つのサービスを置き換えるだけでパイプライン全体を修正しなければならず、開発環境と本番環境の差異による不安定さも受け入れざるを得ません。つまり、生成AIアプリケーション開発における本質的な難しさは、AIモデルの性能ではなく、AIオーケストレーションにあるのです。
既存ワークフローツールの限界
n8n や Zapier といったワークフローツールは確かに存在します。しかし、それらを生成AI開発にそのまま適用するには、構造的な限界があります。これらのツールはサービスごとにノードが分離されており、置き換えが難しく、データフローも静的に固定されています。また、実行中にパラメータを柔軟に調整することができず、繰り返し処理・ループ・履歴管理にも弱いという課題があります。これは、AI特有の反復的な実験や最適化のプロセスを前提として設計されていないことを意味します。
HyperFlow AIの出発点
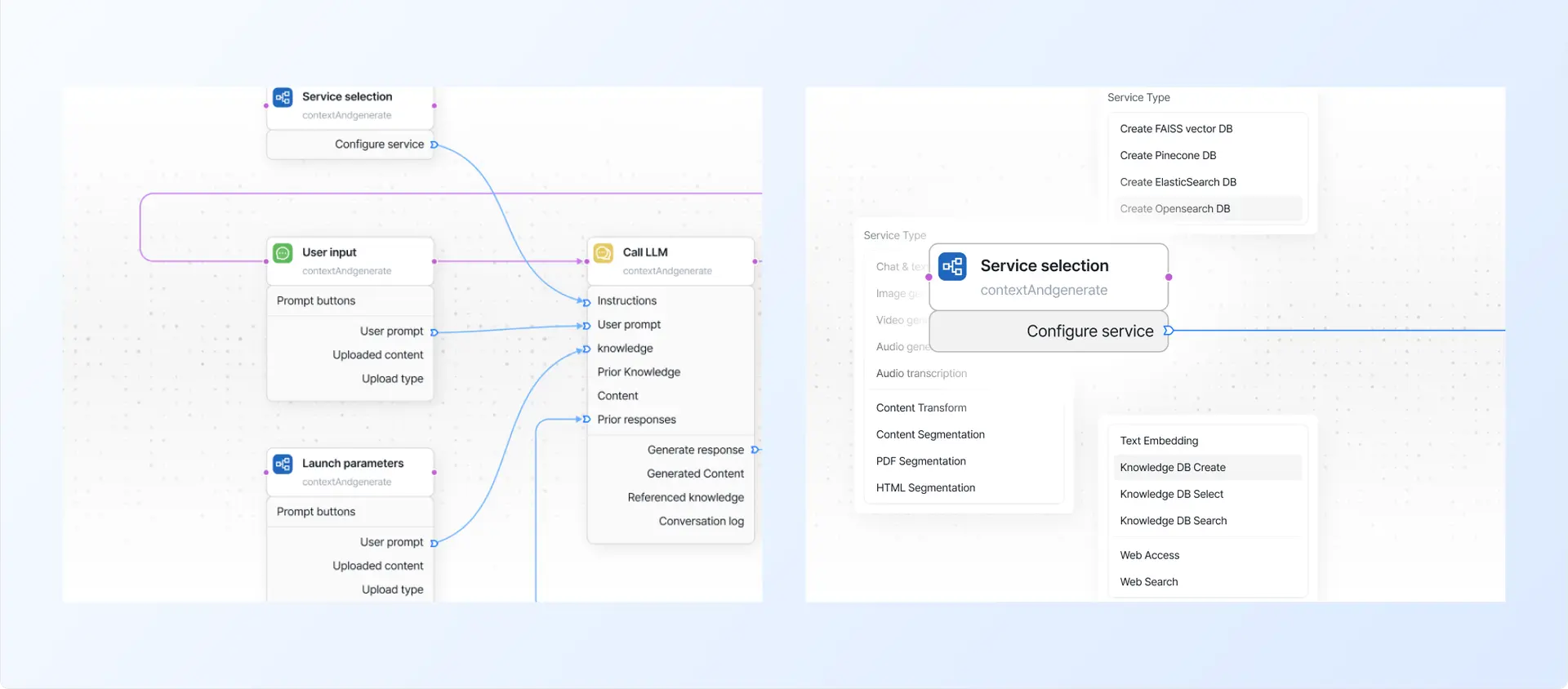
HyperFlowは、生成AIアプリケーションを単一のプログラムとしてではなく、「実行可能なフロー(Flow)」として定義します。そして、そのフローを構成する基本単位は、テキストコードではなく、視覚的に接続される「フローグラフ」です。HyperFlowのフローグラフは、「制御フロー(Process Flow)」「データフロー(Data Flow)」「パラメータフロー(Parameter Flow)」の3つが、1つの統合されたグラフ内で同時に動作するよう設計されています。この構造により、HyperFlowでは以下のような作業がすべて同一の実行モデル上で自然につながります。
- RAGパイプライン
- 複数LLMによる協調処理
- エージェントベースのワークフロー
- 反復実験およびA/Bテスト
- 開発からデプロイへのスムーズな移行
開発とデプロイが分断されない構造
多くのAIシステムは、開発段階では問題なく動作しても、デプロイ後にパラメータ、環境、状態管理の問題によって不安定になるケースが少なくありません。HyperFlowはこれを構造的に解決するため、「開発用実行エンジン」と「運用用実行エンジン」を分離しつつ、同一のフローグラフをそのまま実行できるよう設計されています。つまり、開発過程で実験・検証したフローグラフが、追加の変換なしにそのまま本番アプリケーションとして動作するのです。
技術の本質は「持続可能性」である
HyperFlowが本質的に解決しようとしている課題は、単なる利便性や生産性の向上ではありません。AIモデルやサービスは絶えず入れ替わり、価格・性能・ポリシーも急速に変化しています。このような環境において、アプリケーションの中核ロジックまでが一緒に揺らいでしまえば、そのシステムを長期的に維持することはできません。そこでHyperFlowは、特定のモデルやベンダー、技術スタックに依存しない「構造的抽象化(Architectural Abstraction)」を選択しました。その結果、HyperFlowにおけるワークフローは一度きりの実装物ではなく、時間が経っても価値を保ち続ける「技術資産(IP)」となります。HyperFlowは、単なるノーコード開発ツールを超え、生成AIアプリケーションを拡張性と継続的な運用を前提として設計するための、ひとつの技術的アプローチです。本シリーズでは、HyperFlowを構成する以下の主要技術について、順を追って深く掘り下げていきます。
- HyperFlowのフローグラフ構造
- サービスに依存しないSuper Nodeアーキテクチャ
- パラメータをコードではなく「フロー」として扱う設計
- 開発と運用を分離しない実行モデル
HyperFlow AIは、これらの構造を通じて、生成AIを実験段階にとどめることなく、実際のサービスとして運用するための実行モデルとして定義されます。
